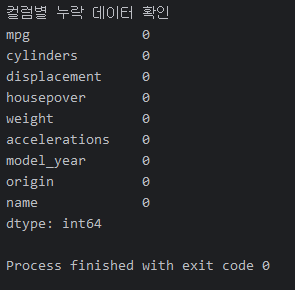
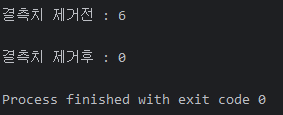
df['horsepower'] = df['horsepower'].replace('?', np.nan)
df['horsepower'] = df['horsepower'].astype('float')
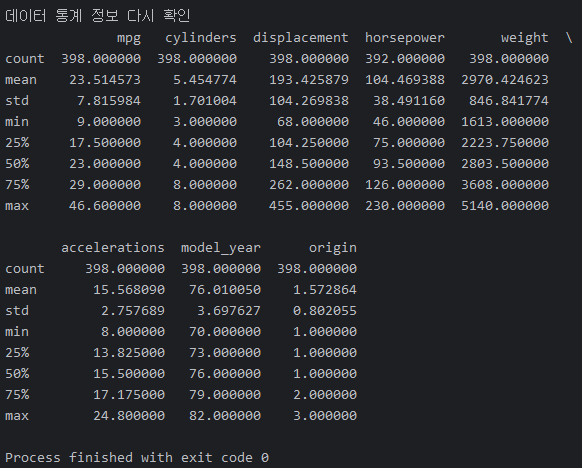
print('\n데이터 통계 정보 다시 확인')
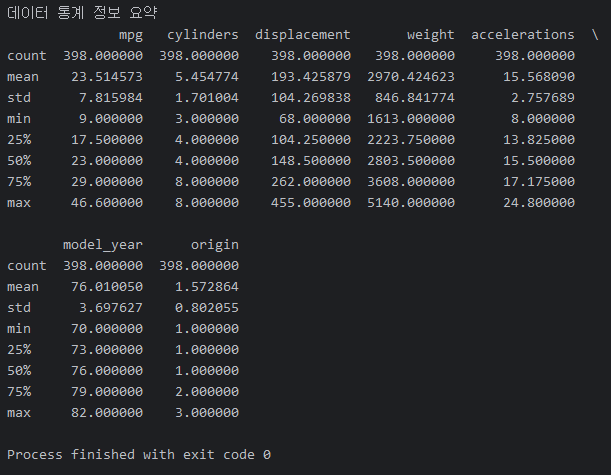
print(df.describe())
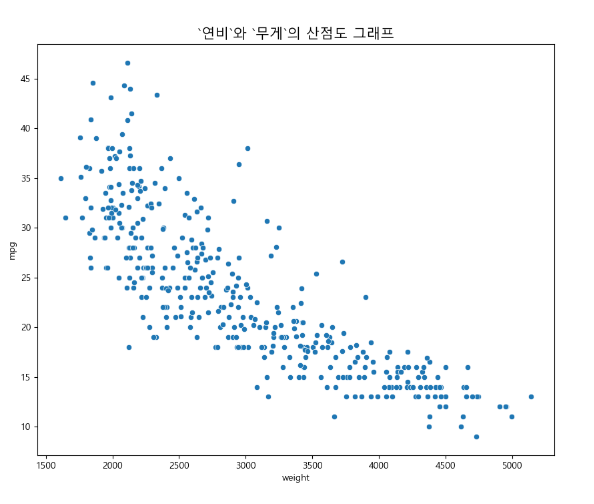
# 독립 변수를 사용하여 종속 변수에 대한 단순 회귀 분석 테스트
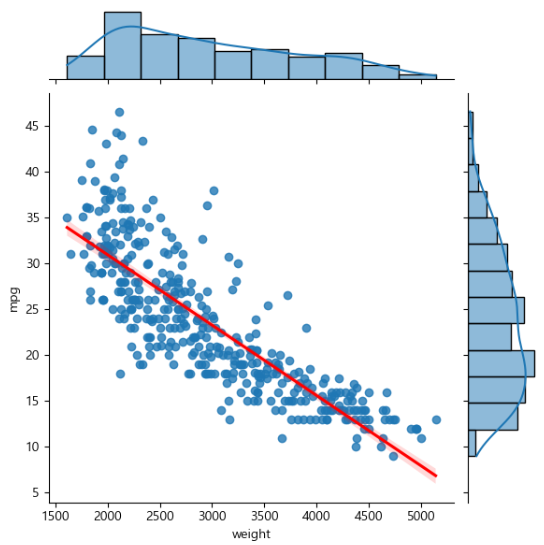
# 회귀선 표시
plt.figure(figsize=(10,8))
# kind='reg' : 회귀선(regression Line) 표시
sns.jointplot(data=ndf, x='weight', y='mpg', kind='reg', line_kws={'color':'red'})
filename = 'jointplot.png'
plt.savefig(dataOut + filename)
print(f'{filename} 파일 생성됨')
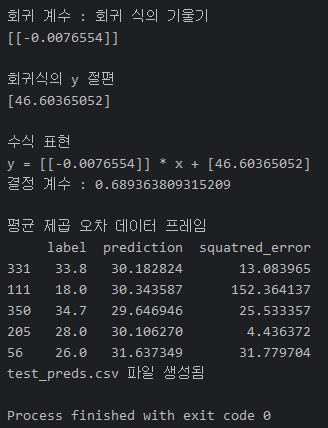
# prediction은 머신 러닝이 학습한 모델을 이용하여 예측해준 정보
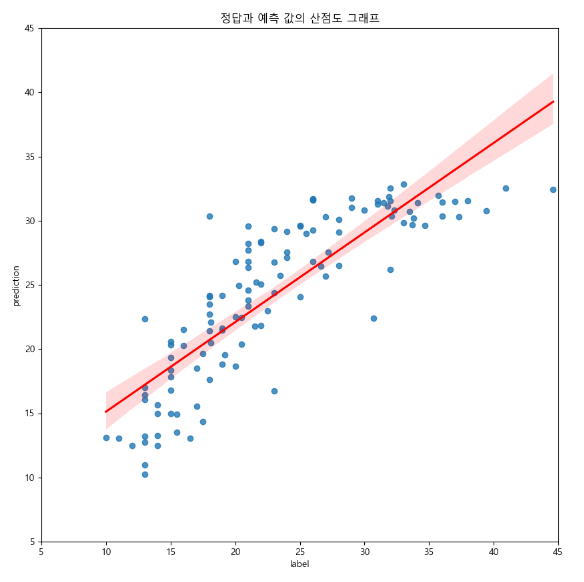
prediction = model.predict(x_test)
# 오차(잔차) 계산
test_preds = pd.DataFrame()
test_preds['label'] = y_test # 실제 정답 데이터를 의미하는 label
test_preds['prediction'] = prediction # 학습한 모델이 예측해준 정보
# (실제정답 - 예측값)의 제곱
test_preds['squatred_error'] = (test_preds['label'] - test_preds['prediction']) ** 2
print('\n평균 제곱 오차 데이터 프레임')
print(test_preds.head())
filename = 'test_preds.csv'
test_preds.to_csv(dataOut + filename, index=False)
print(f'{filename} 파일 생성됨')
# 평균 제곱 오차(mean squared error)
mse = test_preds['squatred_error'].mean()
print(mse)